Internal workings of a HashMap: How it works?
I am a Software Developer based in India.
A HashMap is a part of the Java's Collection and is used to store key-value pairs. Each key is mapped to a single value, and while duplicate keys are not allowed, duplicate values are permitted.
We will learn about how a HashMap works internally, how it stores the the key-value pair, and how it prevents duplicate keys.
//Hashmap Implementation in Java
HashMap<Integer,String> map1 = new HashMap<>();
//Putting different values for different keys
map1.put(1,"Emp1");
map1.put(2,"Emp2");
//Retrieval is possible using the get function
map1.get(101);
//DO NOT COPY
map1.put(101,"Doe");
map1.put(101,"John");
map1.get(101); //Gets the value "John"
//DO NOT COPY
//Duplicate values are allowed
map1.put(102,"John");
map1.put(103,"John");
Many people might perceive HashMap as having a time complexity of O(1) due to its ability to quickly search through large datasets. However, in reality, the Big-O time complexity of HashMap is O(n). But why is this the case?
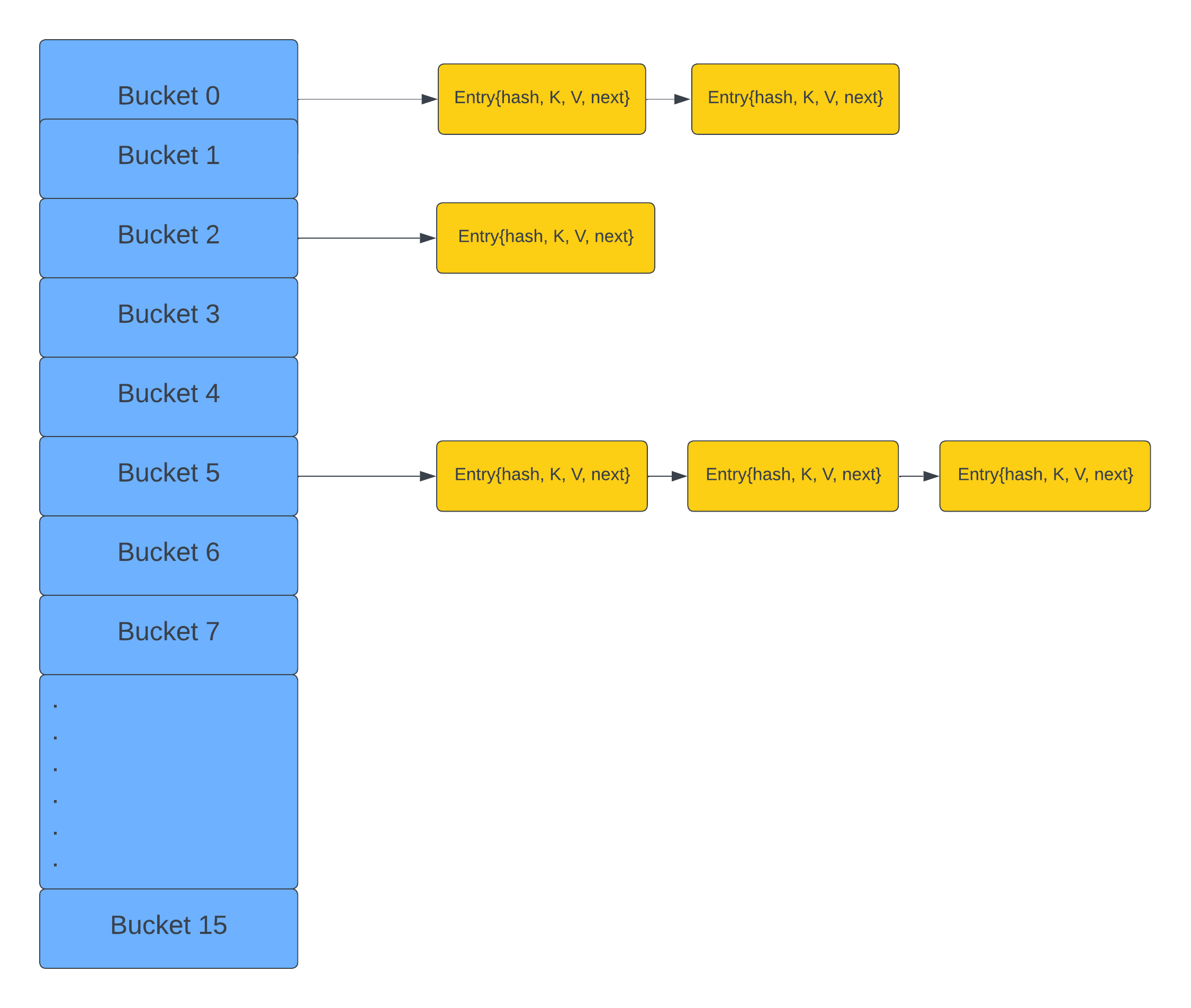
Well, it all boils down to how HashMaps work internally. They operate on the principle of hashing. Each key-value pair is stored as an instance of the Map.Entry interface, typically represented by a Node class. This Node class contains the supplied key, value, the hash of the key object, and a reference to the next Node, if any, forming a linked list structure.
When you perform operations like put() or get() on a HashMap, the hash code of the key is computed to determine the index where the key-value pair should be stored or retrieved. However, in scenarios where multiple keys end up having the same hash code (known as hash collisions), the HashMap resorts to chaining. Chaining involves storing multiple entries with the same hash code in a linked list at the corresponding index.
As a result, in the worst-case scenario where all keys hash to the same index, the time complexity of HashMap operations devolves into O(n), as it needs to traverse through the linked list to find the desired entry. While this situation is rare in practice, it's crucial to understand that the theoretical time complexity of HashMap operations isn't always constant due to the possibility of hash collisions and subsequent chaining."
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
//...
}
The generated hash of the Key object is also stored to avoid calculating hash every time during comparisons, to improve the overall performance.
Internal Implementation of HashMap
The HashMap is a Hashtable-based implementation of the Map interface. Internally, it maintains an array, often referred to as a 'bucket array'. The size of the bucket array is determined by the initial capacity of the HashMap, with the default size being 16.
transient Node<K,V>[] table;
At each index position in the array, a bucket is maintained, capable of holding multiple Node objects. These Node objects are typically organized using a linked list structure
When the number of entries within a single bucket exceeds a predefined threshold (TREEIFY_THRESHOLD, with a default value of 8), the HashMap converts the internal structure of the bucket from a linked list to a Red-Black Tree (The implementation can be found here JEP 180). This transformation involves converting all Entry instances within the bucket to TreeNode instances.
This means that when the number of entries within a single bucket in the map exceeds a certain threshold, HashMap dynamically replaces the linked list implementation of the bucket with an ad-hoc implementation of a Red-Black Tree (TreeMap). As a result, this transformation effectively reduces the time complexity of operations within that bucket from O(n) to O(log n).
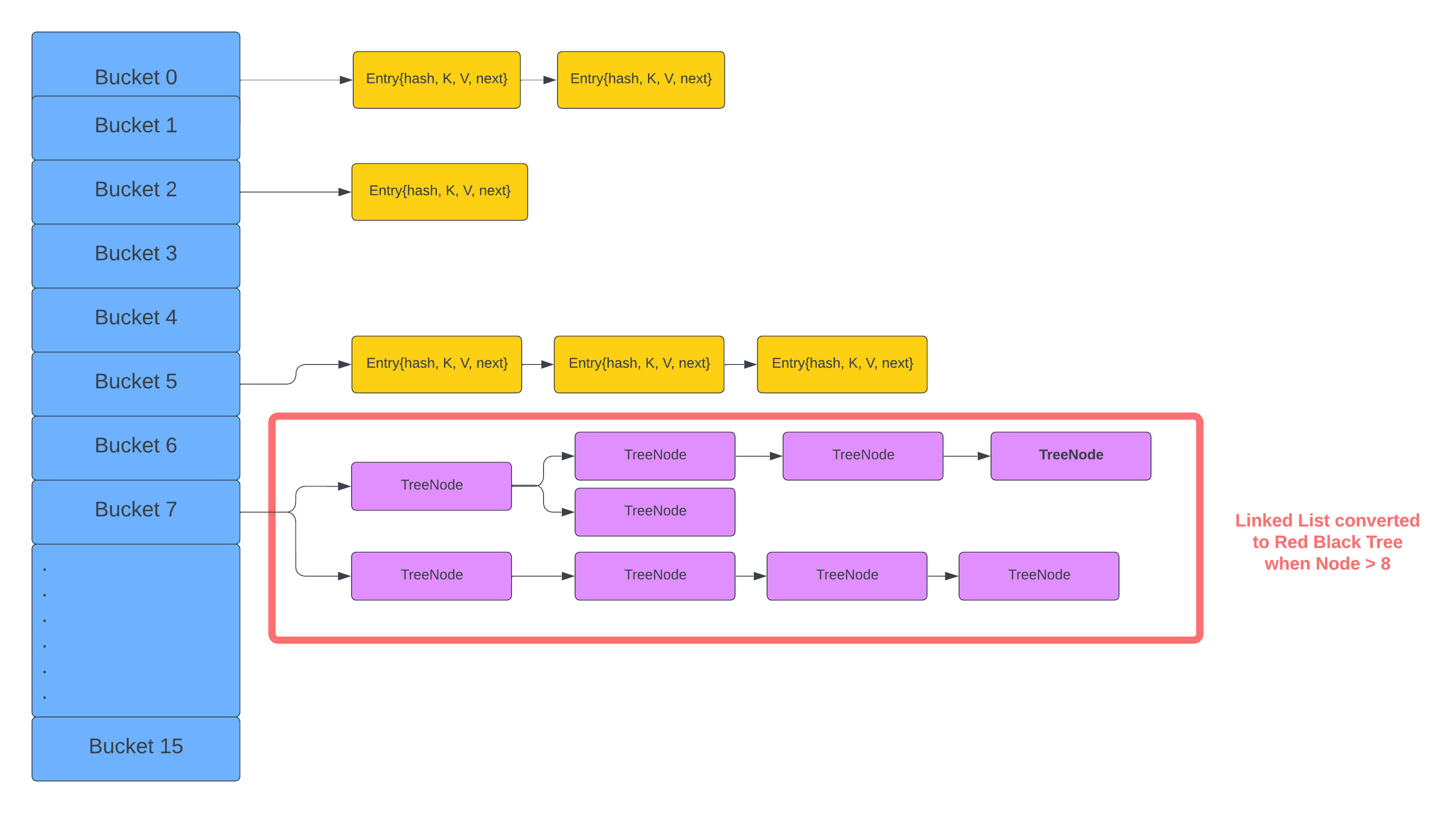
It's worth noting that when the number of nodes within a bucket falls below a certain threshold (UNTREEIFY_THRESHOLD, with a default value of 6), the Red-Black Tree structure is converted back to a linked list. This behavior is designed to balance performance with memory usage, as TreeNodes consume more memory than Map.Entry instances. Therefore, HashMap utilizes a Red-Black Tree structure only when there is a significant performance gain, accepting the trade-off of increased memory consumption.
HashMap.put() Operation
Thus far, we've established that each Java object possesses a unique hash code, which serves as the basis for determining the bucket location in the HashMap where the corresponding key-value pair will be stored.
Before delving into the implementation of the put() method, it's essential to grasp that instances of the Node class are stored in an array. Each index position in this array represents a bucket:
transient Node<K,V>[] table;
To store a key-value pair, we invoke the put() API as follows:
V put(K key, V value);
The put() API internally begins by calculating the initial hash code using the key.hashCode() method. Subsequently, it computes the final hash code using the hash() function to determine the bucket location where the key-value pair will be stored.
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
The final hash value is crucial as it determines the index in the array or the bucket location where the node will be stored
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
After locating the bucket based on the calculated hash code, HashMap proceeds to store the Node within it
How are Collisions Resolved in the Same Bucket?
As we know, two unequal objects can have the same hash code value, leading to a scenario where different objects need to be stored in the same array location, known as a bucket.
In the Node class, there is an attribute called 'next', which always points to the next object in the chain. Therefore, all nodes with equal keys are stored in the same array index in the form of a LinkedList.
When a Node object needs to be stored at a particular index, HashMap checks if there is already a Node present in the array index. If not, the current Node object is stored in this location. However, if an object is already present at the calculated index, HashMap checks its 'next' attribute. If 'next' is null, the current Node object becomes the next node in the LinkedList. This process continues until 'next' is evaluated as null.
It's important to note that while iterating over nodes, if the keys of the existing node and the new node are equal, the value of the existing node is replaced by the value of the new node.
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
break;
}
If the first node in the bucket is of type TreeNode, then the method TreeNode.putTreeVal() is utilized to insert a new node into the Red-Black Tree structure,
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
Thus, we can say that:
If the bucket is empty, the Node is stored directly in the array at the calculated index.
However, if the bucket is not empty, meaning a Node already exists, the current Node is traversed in a LinkedList fashion until either the next node is empty or the keys match. Once an empty next node is found, indicating the end of the LinkedList, the current Node is stored at the last position in the LinkedList.
HashMap.get() Operation
The Map.get() API takes the key object as a method argument and returns the associated value, if it is found in the Map.
String val = map.get("key");
The logic to find the bucket using the get() API is same as the put() API. Once the bucket is located using the final hash value, the first node at the index location is examined.
If the first node in the bucket is of type TreeNode (indicating that the bucket is represented as a Red-Black Tree), the TreeNode.getTreeNode(hash, key) API is employed to search for the key object within the tree. If a TreeNode with a matching key is found, the corresponding value is returned.
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
If the first node in the bucket is not of type TreeNode, (indicating that the bucket is represented as a LinkedList), the search proceeds in a sequential fashion through the nodes. In each iteration, the next attribute of each node is checked until a node with a matching key object is found.
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);